Chapter 2 Significance
Importance of the Problem to Be Addressed. 2,314 exabytes of new medical data was projected to have been produced in 2020 (Stewart, 2020). This sheer volume of health data necessitates the understanding, accessing, managing, and interpreting of data across researchers, clinicians, and patients (Institute of Medicine (US) Roundtable on Value & Science-Driven Health Care, 2010). By democratizing data science skills for clinicians and other biomedical professionals, they will be able to better understand their patient population, better communicate with research teams to improve the outcomes of patients, and be better advocates for their patients. However, existing data science learning materials in the medical and biomedical sciences lack one of the following features: (1) is community oriented, (2) has an open creative commons license, (3) is maintained, (4) is accessible, (5) follows education and pedagogy best practices to target learning objectives, and (6) is domain specific. These are features that would modernize the biomedical data-resource ecosystem, promote Findable, Accessible, Interoperable, and Reusable (FAIR) principles, and enhance the data science and research workforce in the biomedical sciences.
The Health Information Technology for Economic and Clinical Health (HITECH) Act of 2009 included the concept of Electronic Health Records - Meaningful Use (EHR-MU), which incentivized all medical records to be electronic by 2014 (Health and Human Services, 2017; Office for Civil Rights (OCR), 2009; Office of the National Coordinator for Health Information Technology (ONC), 2020). Currently, in 2020 more than 89% of all hospitals have implemented an EHR system (Moriarty, 2020). While EHR systems have their own data challenges, the influx of electronic data has called for changes in how clinicians undergo training to meet the challenges of evidenced-based medicine by using these data (American Medical Association, 2021; Bresnick, 2015). By contextualizing and democratizing data science skills for clinicians, we can provide them more capacity to explore and make better use of the data (Kross et al., 2020). Additionally, by empowering those in or interested in a biomedical profession with better data literacy and data science skills, we can expand the workforce needed to better use and collect the data we need to innovate and progress health care. We can accomplish this skills expansion by teaching learners the programming tools used for data analytics (Farrell and Carey, 2018).
Programming courses are generally inaccessible for someone with a different domain base with high dropout rates and a steep learning curve (Farrell and Carey, 2018; Ogier et al., 2018). Motivation and mindset are some of the integral roles in learning programming and building life-long learners (Ambrose et al., 2010). A backward design approach using learner personas for creating lessons help keep teaching focused on objectives and help cater the needs of the learner to the overall learning objectives (Wilson, 2019). The prevalence of Excel as a data tool guided us to focus on how spreadsheets fit in the data science pipeline and how data literacy concepts, particularly the concept of “tidy data,” can be taught using spreadsheets. Data science tools are built around “tidy data” principles, a core data literacy topic describing how the rows and columns of a data set need to be specified for analysis. Once the lessons are created, it can be freely shared (e.g., using a CC-0 creative commons license) and improved upon, and has the flexibility to be adapted to individual instructor needs.
There is emphasis and need to center materials for individuals in biomedical fields that center around tidy data principles because the data science process requires a tidy dataset to begin the cycle of understanding the data before results can be communicated (Figure 2.1).
![**Standard workflow for data science project.** A data science project has a feedback loop between transforming, modeling, and visualizing data before insights can be communicated. Figure taken from the R for Data Science [@wickhamR4ds].](https://github.com/hadley/r4ds/raw/master/diagrams/data-science.png)
Figure 2.1: Standard workflow for data science project. A data science project has a feedback loop between transforming, modeling, and visualizing data before insights can be communicated. Figure taken from the R for Data Science (Wickham and Grolemund, 2016).
Unfortunately, the process of understanding and drawing conclusions from data is not this linear and requires many smaller feedback loops to account for biases and to tell a more accurate story for a decision (Figure 2.2). Notably, data science products usually end up with some decision or action that will affect the world. This makes each step of the data science process influential to the final set of decisions. Notably, each step of the data science pipeline is a data set, and the data literacy skills needed to process and work with the data in each step is paramount to the final results.
![**Overview of the data life cycle in the research ecosystem** There are many smaller feedback loops between each step in the data science process that affect the final decision, which relate to consequence in the world. This is especially relevant in the biomedical/medical domain [@Chen2020].](https://github.com/chendaniely/data_science-figure/raw/main/fig/data_science_figure.png)
Figure 2.2: Overview of the data life cycle in the research ecosystem There are many smaller feedback loops between each step in the data science process that affect the final decision, which relate to consequence in the world. This is especially relevant in the biomedical/medical domain (Chen, 2020).
This proposal seeks to address the following knowledge gaps in the literature and needs in the field of training biomedical professionals: (1) There are no formal learner personas for the biomedical community and the assessment tools to identify and create learner personas do not exist. (2) Data science learning materials for the biomedical sciences lack community oriented, open, and maintained lessons targeting learner persona needs grounded in pedagogical practices and theory. (3) While we know a lot about the teaching and pedagogy of computer science education, less is known about data literacy education, and almost nothing is known about data science education in an applied domain (e.g., biomedical sciences).
Rigor of Prior Research Supporting the Aims.
Aim 1: Identify learner personas in the biomedical sciences by creating and validating learner self-assessment surveys.
Personas are detailed fictional characters based on well-understood and highly specified data to facilitate user-centered design (Pruitt and Adlin, 2006; Zagallo et al., 2019). Learner personas encompass a learner’s general background, prior relevant knowledge, perception of needs, and special considerations (Wilson, 2019). These personas can be used along with a backwards lesson design method to keep teaching focused on learning objectives, and keep assessment materials within the scope of the learning materials (Wilson, 2019). To identify the learner personas, adaption of questions from The Carpentries (K. Jordan et al., 2018; K. Jordan, 2018; Jordan, 2016; K. L. Jordan, Marwick, Duckles, et al., 2017 `; K. L. Jordan, Marwick, Weaver, et al., 2017; Jordan and Michonneau, 2020), “How Learning Works” (Ambrose et al., 2010), and “Teaching Tech Together” (Wilson, 2019) and focused on 3 knowledge domains: programming knowledge, data knowledge, and statistics knowledge will be created. This learner self-assessment study will be critical in determining who will engage in this material, what needs exist in the current spectrum of knowledge, and avenues to deliver content and competencies. Personas will be crafted based on the 3 knowledge domains in data science and will be sent out to list serves and results can be clustered to identify personas using hierarchical clustering (Zagallo et al., 2019). The personas created can help future educators in the biomedical sciences teaching data science skills focus their content, so they are relevant to the population and address their needs. The survey and persona clustering methodology can be adapted and utilized to create data science materials for other professional domains.
Previous studies and preliminary data highlight the ability of clustering to identify personas (Figure 2.3). The identified clusters were combined with the original survey data to fill in each persona’s prior relevant knowledge and background. The perception of needs and special considerations were created to make each persona complete but not based on survey data. A future qualitative study would be needed to get a more accurate background, need, and special considerations for the personas (Zagallo et al., 2019). Preliminary data also suggests that the survey is internally consistent and valid. However, a larger sample size across a wider geographic area would be needed to externally validate the survey.
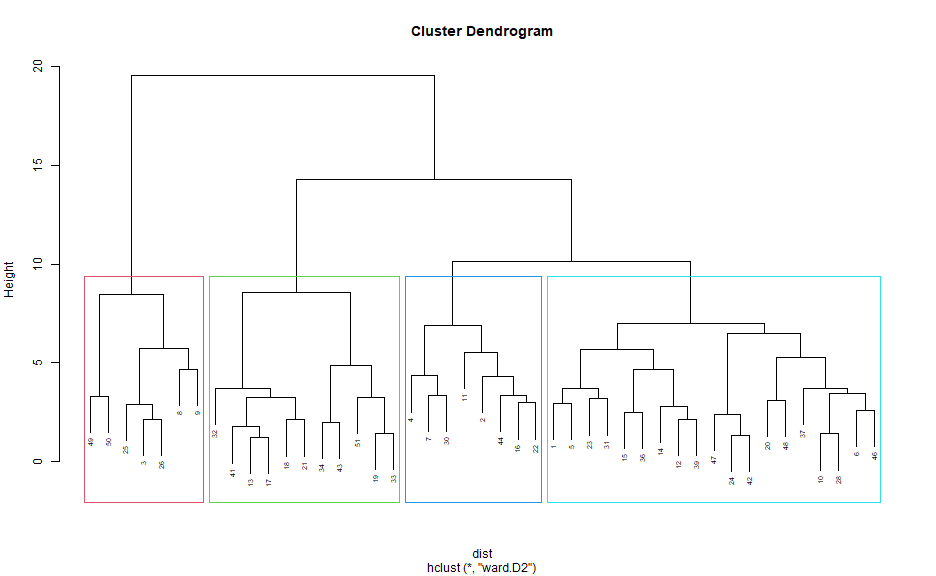
Figure 2.3: Learner self-assessment clusters. Four clusters created from the hierarchical clustering using Euclidean distance and Ward’s method as based on preliminary data of the learner self-assessment survey. From left to right: experts (red), clinicians (green), students (blue), and academics (teal).
Aim 2: Create an effective data science for biomedical science curriculum based on best education and pedagogy practices.
Create a data science curriculum for the biomedical sciences using a backwards design approach. This puts the learning objectives, formative and summative assessment questions at the forefront of the lesson material to keep them focused and in the scope of the lesson (Wilson, 2019). Learners who want to learn how to perform data analysis, typically, also need to learn data literacy skills to learn how to obtain and manipulate data (Milo, 2005). Tidy data principles will be employed as the guiding concept of data literacy (Wickham, 2014) to focus our learning objectives. Best practices on education and pedagogy dictate small, focused lessons and reinforce the learning objectives by creating a series of formative assessments (Ambrose et al., 2010; Wilson, 2019). To test the content and effectiveness of the materials and its learning objectives, we use a series of pre-workshop and post-workshop surveys to determine learner’s confidence in the learning objectives (K. Jordan et al., 2018; Jordan, 2016; K. L. Jordan, Marwick, Duckles, et al., 2017).
A long-term survey will be sent out to respondents to see how their confidence with the same set of learning objectives change over 6 months, to see how learners may have retained and built on the knowledge from the workshop. There is a final summative assessment question in both the post-workshop and long-term survey. This work will serve as the first set of (1) community-oriented, (2) open with a creative commons license, (3) accessible, (4) follows best pedagogical practices, and (5) domain specific surveys and learning materials. Maintainability needs to be accessed over longer periods of time, but organizations like The Carpentries provide a community and mechanism where these materials can be migrated to after the initial curriculum assessment is complete to find other lesson maintainers in their incubator and lab community lessons. The surveys will be published to be used in other workshops and adapted to other domains.
Aim 3: Assess the effectiveness of formative assessments in learning objectives.
Formative assessments are a pedagogical tool that instructors use to identify learner’s misconceptions (Wilson, 2019). In order to reduce the cognitive load on the learners, various types of assessment questions can be used. Parson’s problems take a block of solution code, scramble the order of the lines, and ask the learner to assemble the code back into the correct execution order (Wilson, 2019). Faded’s examples provide working code snippets with some amount of the code “blanked out” (Wilson, 2019). Parson’s problems allow the learner to focus on the overall steps and flow of the thought process, and Faded’s examples focus the learner’s attention to a specific part of the code. Both provide some kind of scaffolding mechanism for the student, so they are not writing code from scratch. These assessments will look for time to complete and solution correctness as a measure of meeting the learning objectives. It will also be the first set of data science specific formative assessments focused on data literacy topics, and not basic programming concepts in the computer science literature. By using the learning materials from Aim 2 and the assessment tools focused on learning objectives we will create a summative assessment question. We expect to have better learning outcomes in the learners when concepts are reinforced with formative assessment questions that guide the learner to aspects of the code that are incorrect, rather than simply telling them the solution they provided is incorrect (Figure 2.4).
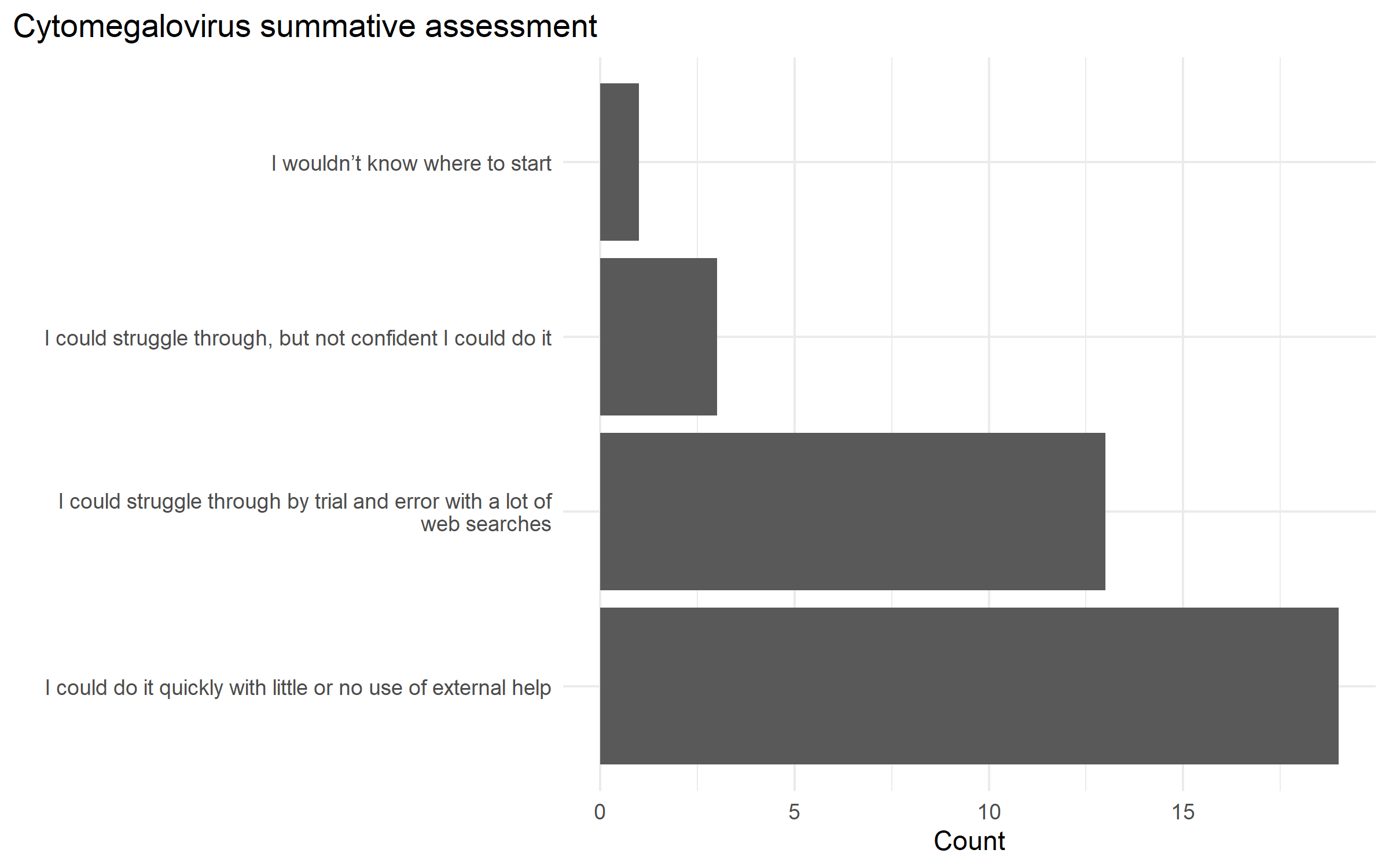
Figure 2.4: Example summative assessment response in post-assessment survey. The question asked the learners about a learner’s comfort and ability in loading a tabulated dataset, cleaning the data, and performing a statistical analysis to answer a question on the topic of cytomegalovirus.
Significance of the Expected Research Contribution.
Upon successful completion of the proposed studies, we expect our contribution to be a framework of how to create domain specific data science learning materials. The learner personas developed in Aim 1 will be used when teaching data science to new learners in the medical and biomedical sciences. The surveys used to create the personas can be used to other domains which can inform instructors about their learners. In addition, we are performing one of the few studies to date that look into how students learn in a data literacy and data science context, in connectivity to an applied field, not in a computer science context. This contribution is expected to be significant because of the growing need in the biomedical workforce for data science education. We are not only creating data science learning materials following best education and pedagogical practices, but also creating a curriculum in the biomedical sciences domain along with the tools and framework for expanding the content to other domains. Additionally, formative assessment questions will be measured for their effectiveness in learning the data science and data literacy contexts.
References
Ambrose, S. A., Bridges, M. W., DiPietro, M., Lovett, M. C., and Norman, M. K. (2010). How learning works: Seven research-based principles for smart teaching. John Wiley & Sons.
American Medical Association. (2021). Accelerating Change in Medical Education. American Medical Association. https://www.ama-assn.org/education/accelerating-change-medical-education
Bresnick, J. (2015, November 2). Healthcare Big Data Analytics in Med School Marks Turning Point. HealthITAnalytics. https://healthitanalytics.com/news/healthcare-big-data-analytics-in-med-school-marks-turning-point
Chen, D. (2020, December). Data science figure. https://github.com/chendaniely/data_science-figure
Farrell, K. J., and Carey, C. C. (2018). Power, pitfalls, and potential for integrating computational literacy into undergraduate ecology courses. Ecology and Evolution, 8(16), 7744–7751. https://doi.org/10.1002/ece3.4363
Health and Human Services, U. S. D. of. (2017). HITECH Act Summary. https://www.hipaasurvivalguide.com/hitech-act-summary.php
Institute of Medicine (US) Roundtable on Value & Science-Driven Health Care. (2010). Clinical Data as the Basic Staple of the Learning Health System. In Clinical Data as the Basic Staple of Health Learning: Creating and Protecting a Public Good: Workshop Summary. National Academies Press (US). https://www.ncbi.nlm.nih.gov/books/NBK54306/
Jordan, K. (2018). Analysis of The Carpentries Long-Term Impact Survey. Zenodo. https://doi.org/10.5281/zenodo.1402200
Jordan, K. (2016). Data Carpentry Assessment Report: Analysis of Post-Workshop Survey Results. Zenodo. https://doi.org/10.5281/zenodo.165858
Jordan, K. L., Marwick, B., Duckles, J., Zimmerman, N., and Becker, E. (2017). Analysis of Software Carpentry’s Post-Workshop Surveys. Zenodo. https://doi.org/10.5281/zenodo.1043533
Jordan, K. L., Marwick, B., Weaver, B., Zimmerman, N., Williams, J., Teal, T., Becker, E., Duckles, J., Duckles, B., and Wickes, E. (2017). Analysis of the Carpentries’ Long-Term Feedback Survey. Zenodo. https://doi.org/10.5281/zenodo.1039944
Jordan, K. L., and Michonneau, F. (2020). Analysis of The Carpentries Long-Term Surveys (April 2020). Zenodo. https://doi.org/10.5281/zenodo.3728205
Jordan, K., Michonneau, F., and Weaver, B. (2018). Analysis of Software and Data Carpentry’s Pre- and Post-Workshop Surveys. Zenodo. https://doi.org/10.5281/zenodo.1325464
Kross, S., Peng, R. D., Caffo, B. S., Gooding, I., and Leek, J. T. (2020). The Democratization of Data Science Education. The American Statistician, 74(1), 1–7. https://doi.org/10.1080/00031305.2019.1668849
Milo, S. (2005). Information literacy, statistical literacy, data literacy. IASSIST Quarterly, 28(2-3), 6–6.
Moriarty, A. (2020, May 26). Does Hospital EHR Adoption Actually Improve Data Sharing? Definitive Healthcare. https://blog.definitivehc.com/hospital-ehr-adoption
Office for Civil Rights (OCR). (2009, October 28). HITECH Act Enforcement Interim Final Rule [Text]. HHS.gov. https://www.hhs.gov/hipaa/for-professionals/special-topics/HITECH-act-enforcement-interim-final-rule/index.html
Office of the National Coordinator for Health Information Technology (ONC). (2020, May 19). Health IT Legislation. https://www.healthit.gov/topic/laws-regulation-and-policy/health-it-legislation
Ogier, A., Brown, A., Petters, J., Hilal, A., and Porter, N. (2018). Enhancing Collaboration Across the Research Ecosystem: Using Libraries as Hubs for Discipline-Specific Data Experts. Proceedings of the Practice and Experience on Advanced Research Computing, 1–6. https://doi.org/10.1145/3219104.3219126
Pruitt, J., and Adlin, T. (2006). The Persona Lifecycle: Keeping People in Mind Throughout Product Design (1st edition). Morgan Kaufmann.
Stewart, C. (2020, September 24). Healthcare data volume globally 2020 forecast. Statista. https://www.statista.com/statistics/1037970/global-healthcare-data-volume/
Wickham, H. (2014). Tidy Data. Journal of Statistical Software, 59(1, 1), 1–23. https://doi.org/10.18637/jss.v059.i10
Wickham, H., and Grolemund, G. (2016). R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. O’Reilly Media. https://r4ds.had.co.nz/
Wilson, G. (2019). Teaching tech together: How to make your lessons work and build a teaching community around them. CRC Press.
Zagallo, P., McCourt, J., Idsardi, R., Smith, M. K., Urban-Lurain, M., Andrews, T. C., Haudek, K., Knight, J. K., Merrill, J., Nehm, R., and others. (2019). Through the eyes of faculty: Using personas as a tool for learner-centered professional development. CBE—Life Sciences Education, 18(4), ar62.