Your first chat with an LLM 🗣️🤖
Working with an LLM
Many different chat providers
- OpenAI ChatGPT
- Anthropic Claude
- Google Gemini
- xAI Grok
- Meta Llama
etc…
Demo: OpenAI ChatGPT
from pprint import pprint
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv() # Loads OPENAI_API_KEY from the .env file
# Creates an OpenAI client, which can be used to access any OpenAI service
# (including Whisper and DALL-E, not just chat models). It's totally stateless.
client = OpenAI()
# The initial set of messages we'll start the conversation with: a system
# prompt and a user prompt.
messages = [
{"role": "system", "content": "You are a terse assistant."},
{"role": "user", "content": "What is the capital of the moon?"},
]
# Call out to the OpenAI API to generate a response. (This is a blocking call,
# but there are ways to do async, streaming, and async streaming as well.)
response = client.chat.completions.create(
model="gpt-4.1",
messages=messages,
)
# Print the response we just received.
print(response.choices[0].message.content)
# If you want to inspect the full response, you can do so by uncommenting the
# following line. The .dict() is helpful in getting more readable output.
# pprint(response.dict())
# The client.chat.completions.create() call is stateless. In order to carry on a
# multi-turn conversation, we need to keep track of the messages we've sent and
# received.
messages.append(response.choices[0].message)
# Ask a followup question.
messages.append({"role": "user", "content": "Are you sure?"})
response2 = client.chat.completions.create(
model="gpt-4.1",
messages=messages,
stream=True,
)
for chunk in response2:
print(chunk.choices[0].delta.content or "", end="", flush=True)
print()GitHub Models
GitHub Models: https://github.com/marketplace/models
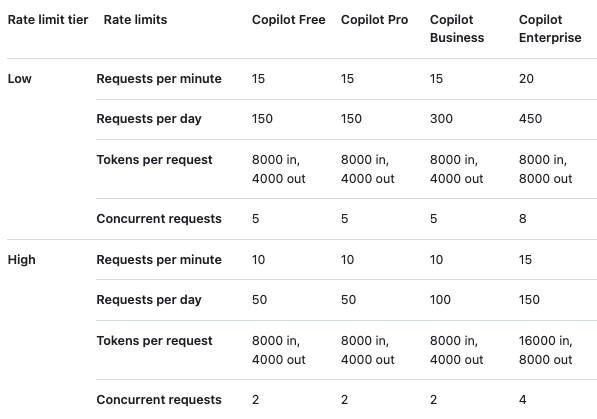
- Free tiers of all the latest models
- Playground to tinker with them
https://docs.github.com/en/github-models/use-github-models/prototyping-with-ai-models#rate-limits
Your turn: OpenAI / GitHub
05:00
Note
Make sure you have created a GitHub PAT (you do not need any specific context)
import os
from pprint import pprint
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
# arguments passed switch to using GitHub models
client = OpenAI(
api_key=os.environ["GITHUB_TOKEN"],
base_url="https://models.inference.ai.azure.com"
)
messages = [
{"role": "system", "content": "You are a terse assistant."},
{"role": "user", "content": "What is the capital of the moon?"},
]
response = client.chat.completions.create(
model="gpt-4.1",
messages=messages,
)
print(response.choices[0].message.content)
messages.append(response.choices[0].message)
messages.append({"role": "user", "content": "Are you sure?"})
response2 = client.chat.completions.create(
model="gpt-4.1",
messages=messages,
stream=True,
)
for chunk in response2:
print(chunk.choices[0].delta.content or "", end="", flush=True)
print()Educator Developer Blog
How to use any Python AI agent framework with free GitHub Models
Demo: Langchain
from dotenv import load_dotenv
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
load_dotenv() # Loads OPENAI_API_KEY from the .env file
# Create an OpenAI chat model, with conversation history.
# See https://python.langchain.com/docs/tutorials/chatbot/ for more information.
# The underlying chat model. It doesn't manage any state, so we need to wrap it.
model = ChatOpenAI(model="gpt-4.1")
# This is how you provide a system message in Langchain. Surprisingly
# complicated, isn't it?
prompt = ChatPromptTemplate.from_messages(
[
SystemMessage("You are a terse assistant."),
MessagesPlaceholder(variable_name="messages"),
]
)
# Wrap the model and prompt up with some history.
history = InMemoryChatMessageHistory()
client = RunnableWithMessageHistory(prompt | model, lambda: history)
# We're ready to chat with the model now. For this example we'll make a blocking
# call, but there are ways to do async, streaming, and async streaming as well.
response = client.invoke("What is the capital of the moon?")
print(response.content)
# The input of invoke() can be a message object as well, or a list of messages.
response2 = client.invoke(HumanMessage("Are you sure?"))
print(response2.content)Different chat APIs
Each Chat API can have a different JSON payload, functions, ways to construct the chat history, etc…
Chatlas + Ellmer
Unify the prompt creation process and steps
Demo: Chatlas + Ellmer (OpenAI)
Python Chatlas
from chatlas import ChatOpenAI
from dotenv import load_dotenv
load_dotenv() # Loads OPENAI_API_KEY from the .env file
chat = ChatOpenAI(model="gpt-4.1", system_prompt="You are a terse assistant.")
chat.chat("What is the capital of the moon?")
chat.chat("Are you sure?")R Ellmer
library(dotenv) # Will read OPENAI_API_KEY from .env file
library(ellmer)
chat <- chat_openai(
model = "gpt-4.1",
system_prompt = "You are a terse assistant.",
)
chat$chat("What is the capital of the moon?")
# The `chat` object is stateful, so this continues the existing conversation
chat$chat("Are you sure about that?")Demo: Chatlas + Ellmer (Claude)
Python Chatlas
from chatlas import ChatAnthropic
from dotenv import load_dotenv
load_dotenv()
chat = ChatAnthropic(model="claude-3-7-sonnet-latest", system_prompt="You are a terse assistant.")
chat.chat("What is the capital of the moon?")
chat.chat("Are you sure?")R Ellmer
Your turn: Chatlas Ellmer GitHub
10:00
Python Chatlas
import os
from chatlas import ChatGithub
from dotenv import load_dotenv
load_dotenv()
chat = ChatGithub(
model="gpt-4.1",
system_prompt="You are a terse assistant.",
api_key=os.getenv("GITHUB_PAT"),
)
chat.chat("What is the capital of the moon?")
chat.chat("Are you sure?")R Ellmer
MDS AI Mini-Workshop. 2025. https://github.com/chendaniely/2025-06-05-llm